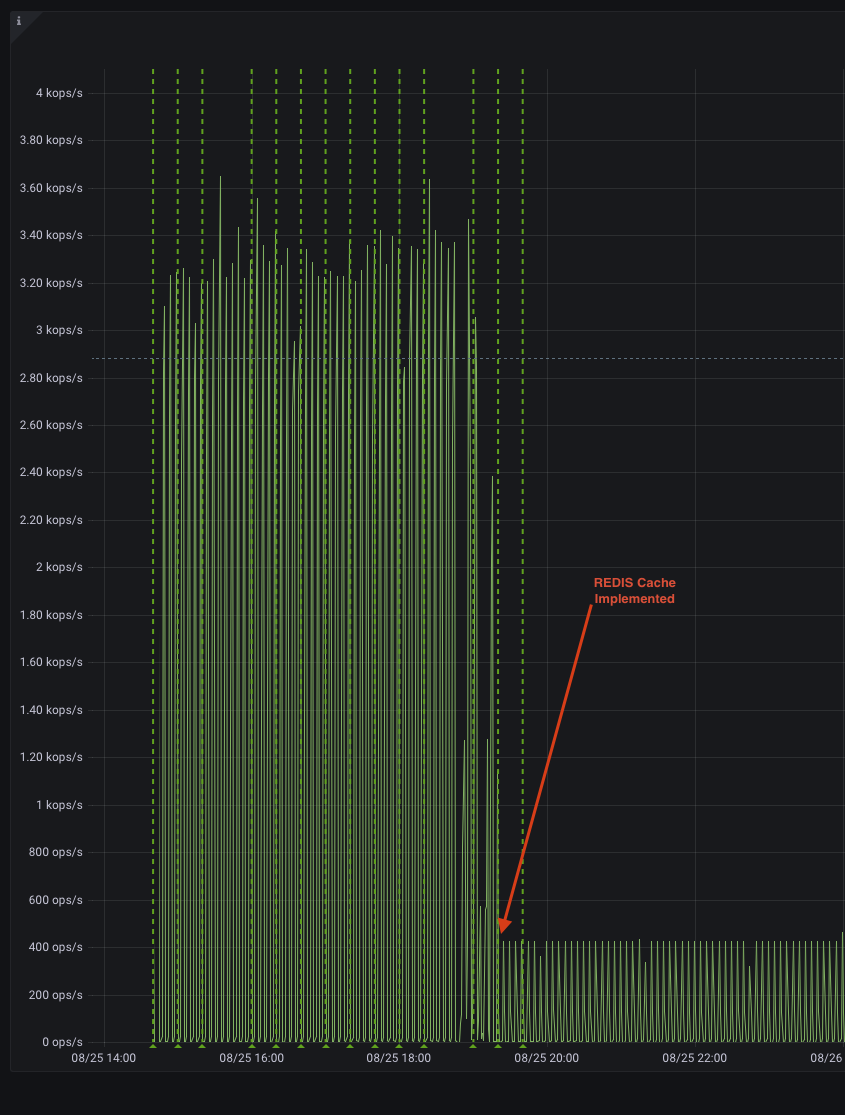
We noticed that our larger hosts, specifically PoP routers with thousands of interfaces were having intermittent resource graphing. This seemed strange since we have a Scylla backend we are using with NewTS that has gobs of resources. The Horizon server is also fine resource wise, well as it turns out, implementing the REDIS cache for OpenNMS/Horizon makes a world of difference.
In our case we went from ~3600/sec queries against the Scylla cluster to ~450/sec and all graphing gaps went away. Also viewing resource graphs got faster. It would appear that the internal Cache in Horizon may just not be powerful enough and is not very efficient when compared to REDIS.